
Atlassian Datacenter 产品介绍
云端原本就是群集化的架构,开发团队应用Atlassian 系列产品已经相当广泛,但是将应用程序作为节点(比如Jira,confluence,bamboo…等應用程式)然后群集化的运维团队却是少之又少,希望以基础架构的角度切入,由以下列举之细目引导大家了解 Altassian DataCenter这个 群集化的方案,进而盘点要建置DataCenter,到底需要哪些第三方技术才能够完整这样的架构:
群集化不可或缺的虚拟环境 (Virtualization):
以一个节点为单位,虚拟节点当然要比实体节点好调度,而且群集化后的节点群,要在实体机之间迁移,没有俱备虚拟环境要如何轻易的完成这样的任务。要发挥DataCeneter所带来的好处,虚拟环境是必备的条件之一,且并不需要在特定的虚拟产品下运行。
如下知名的虚拟産品所建构的虚拟环境都可以
针对负载平衡,也许客户会列举出运行中的 jira 负载还好,不需要用到负载平衡。但是双机热备HA,就不单单只是在性能或是备援的考量,反而是应用面。怎么说呢?相信在应用程序或是插件的升级需求大家都有,但要在哪个节点测试呢?为了测试多买一套应用程序吗?就算预算充裕,那测试完毕确认是可以满足开发人员需求,接下来要如何在不干扰下把在线人员整个移转过来?还是就在线直接更新。在线直接更新是大部份目前的作法,所产的问题状况百出,有时还回复不了原始状态,轻则中断开发人员的应用,重则数据遗失。也因此,有了 DataCenter 的应用程序再加上 Pacemaker 所建置完善的双机热备,那么整个应用程序的群集或是插件的应用就拥有了顺畅的演化环境,相关的升级就可以放手去进行,前端开发团队所提出的需求也能快速反应。
(pacemaker,corosync) 双机热备首选技朮
全新建置的节点,在这里建议大家采用 CentOS or RedHat 7 也就是 Linux 核心是 3.10,pacemaker 建置过程有稍稍较之前 Redhat or CentOS 5~6 较依赖 cli(command line)但整个建置完善后,不管是节点之间服务切换的速度,或是一些故障分析,都较能经得起考验。
当然维持原有的 Linux HA 旧环境,或是操作系统版本有需要让其他软件依赖的考量而无法升级,DataCenter 的架构仍然是可以完成的。只是在多节点的布署,操作系统最好选择以 Linux 核心为 3.10 来担任。
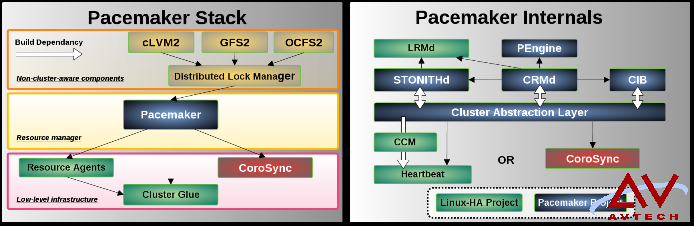
以下两张分别为 pacemaker 的堆栈及内构图示:
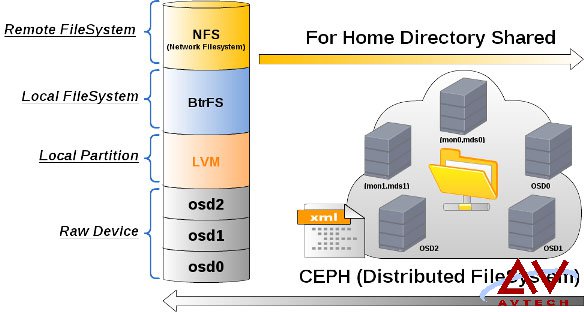
Home-shared 是 DataCenter 的一个关键,原本 Atlassian 系列的应用程序都有一个 Local Home,透过 NFS 这个网络文件系统让同一种 AP 多个节点,供享同一个 home directory。如此协同运作,就可以让单一个节点所作的设置(比如插件升级或是安装),群集里的其他成员也就跟着完成。
NFS 的供应端可以是任何云存储的分布式文件系统技术,这里用 CEPH 为示例来作说明,前端是藉由 NFS 分享出来的网络文件系统,后端是由三个 osd 节点组合出来的 RAW device,接下来是一个有趣的组合,我把监控 mon 和元数据 msd 原来两个节点组合为一个节点总共两组,这样就可以为 NFS-server 建置一个 HA 也就是提供一个虚拟 IP 给 Atlassian AP 作挂载,这样 share home 就有了热备援啦!在这里的 Pacemake 建置 HA 主要是为了 NFS-server 服务,mon 及 msd 的组合节点原本就有热备援的机制存在,不需要依赖 Packmaker 的 HA。
请以下面图型来想像一下我所描述的安排:
DRBD 只提供到 Raw Device,再上层的文件系统就由操作系统接手了,接下来的挂载再由 Pacemaker 安排,DRBD 模块负责着三个访问(Raw Driver,Disk Driver,NIC Driver)。
这里写图片描述
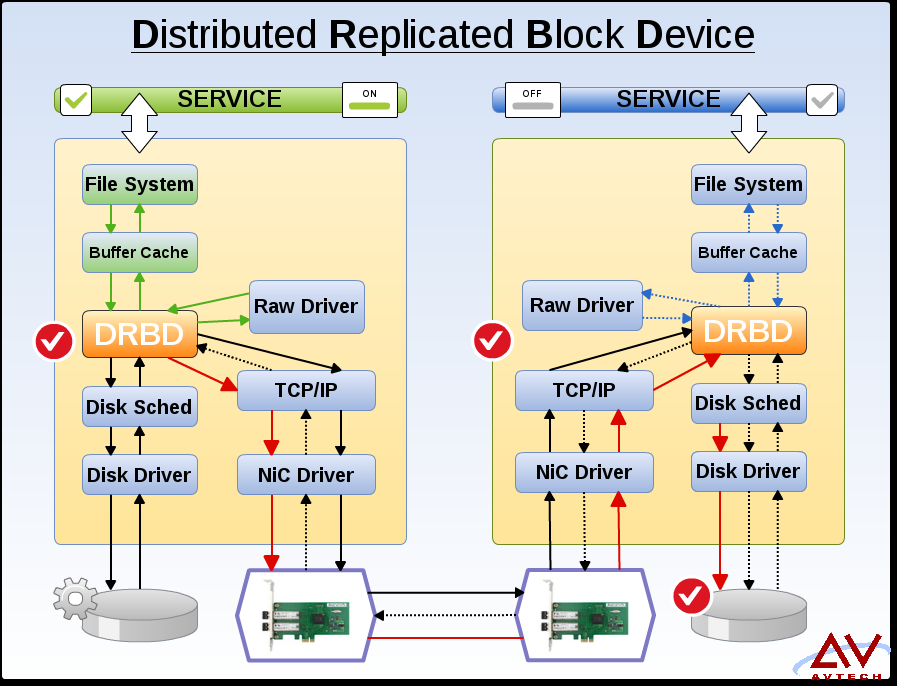
再次提醒: DRBD的存储构架,对群集而言只适合集成双机热备构架也就是HA,不合适负载均衡的安排,这点请注意。
负载均衡 (LoadBalance)
HAproxy 是个非常不错的负载均衡舵手,在这个角色下可以用简单的参数来调配,可以作到让出来面对客户端提出需求的 web-service 群,是用什么样的模式来运作。比如 roundrobin 或 static-rr ,甚至可以分头顾及到下层的数据库是不是采用 leastconn 模式。
当然 HAproxy 这么重要的网关怎么可以只由单一的节点来担任,再建一组 HA 吗?一个很有趣的安排,把 HAproxy 往群里面配,不管是由云存储的群(sql)或是云计算的群(html)都可以,只要把群里每个成员上的 HAproxy 服务全部启动,参数调配好后就由 Pacemaker 所供应出来的虚拟IP来面对客户端的需求访问,这样 HAproxy 就有热备援的机制啦!
可以参考如下的图示想像一下这个有趣的安排。
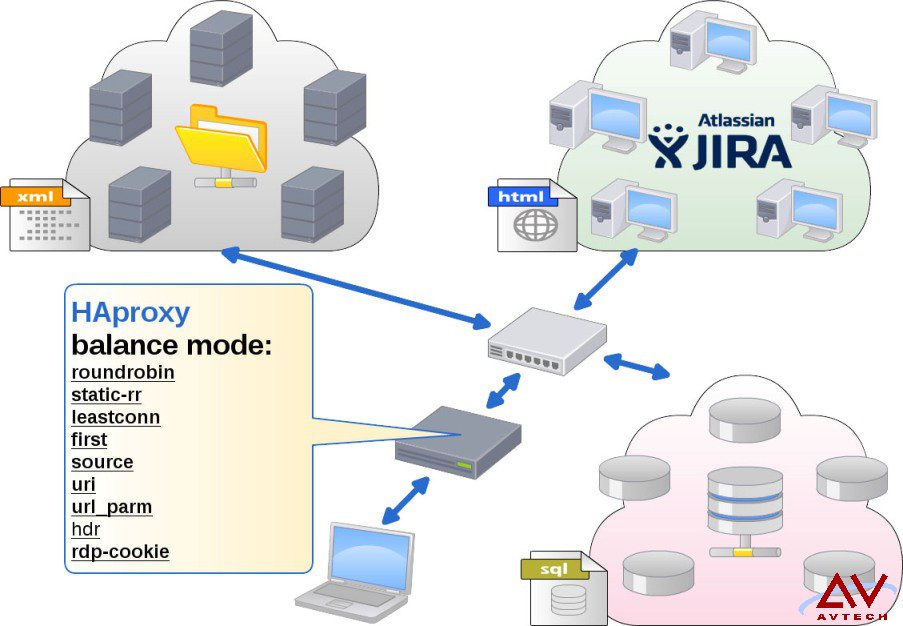
2.static-rr:平输询在各个节点上,但权重调整无效。不管各个服务器规格如何,按总节点数平圴轮询。
3.leastconn:適合sessions較長的服務端,比如 LDAP,SQL….等,權重調整後會較緩慢生效。
4.first:该算法的目的是要始终使用最小服务器的数量。
5.source:这确保了同一客户端地址将始终达到相同的服务器端。
6.url:同 source 差别在用 url 来辨别客户端。
7.url_arm:同 url 差别在有参数,一般是服务器对服务器的访问。
8.hdr:这一般指的是可识别的用户标头,也就是同一个用户帐号登入不同客户端作访问服务器,都是由同一台服务器来服务。
9.rdp-cookie:如同 hdr 但以 cookie 存在与否来判别是否改变访问的主机。
设置步骤 (DataCenter Setup)
以下为 Atlassian 原厂 DataCenter for jira 的设置步骤
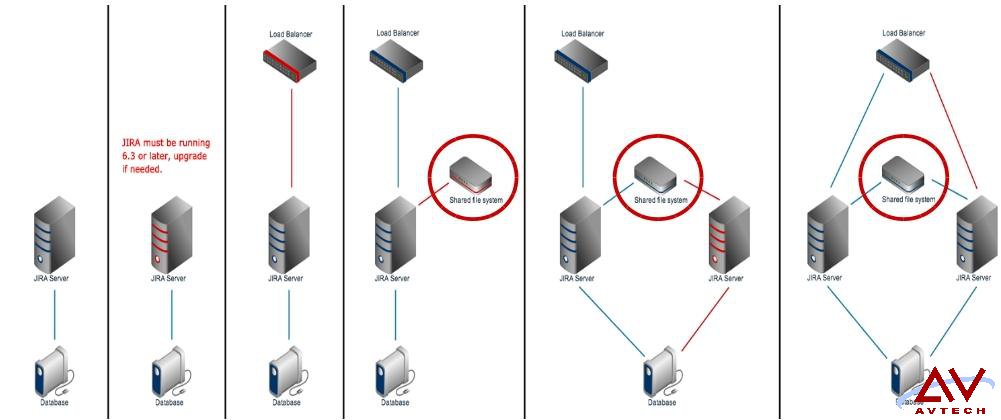
2.确认原本的 jira 版本是在 6.3 以上(含),如果版本条件不满足,请先进行升级或是改版计划。
3.将 Loadblance 的节点安排好,这篇文章建议的是 HAproxy 服务器。
4.把 Local Home Directory 分享出来,作为 DataCenter 最重要的 Share Home 的一个位置。
5.加入第二个应用程序节点,把数据库设定好,NFS-client 设定好访问 Shared Home。
6.将 HAproxy 上层之AP设定为 roundrobin 模式,将下层数据库设定为 lessconn 模式,然后全部串接起来,由 Pacemaker 建置好的虚拟 IP,准备接受客户端的访问。
效能监控工具 (Performance Monitor)
在建置 DataCentor 的整个过程还算繁琐,不只步骤繁多,构架多样化,但整个模型是一致的,会建构 jira 应用程序的 DataCenter 也就会建构其他应用程序的 DataCenter,整个过程中,在这里建议随时观测虛拟环境的效能监控工具,一边进行建置一边进行诊断,才不㑹进行了大部份的建构步骤才开始回头查问题的原因,那将㑹增加问题分析的困难度。
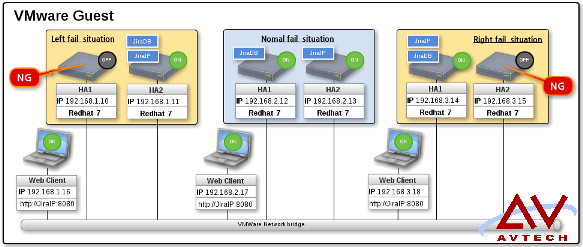
如下图标示例,在我们浏览 jiraIP 我们可以知道 ha1 和 ha2 彼此之间并非 roundrobin 关系:
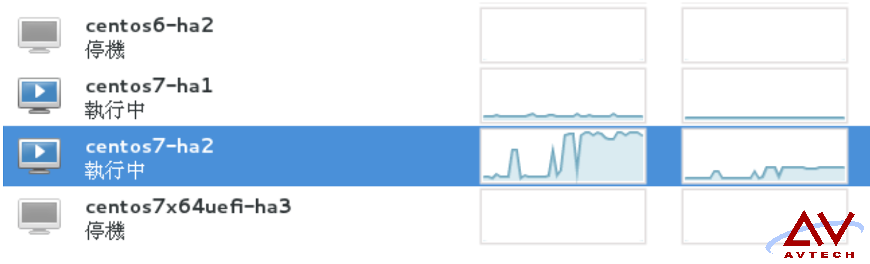
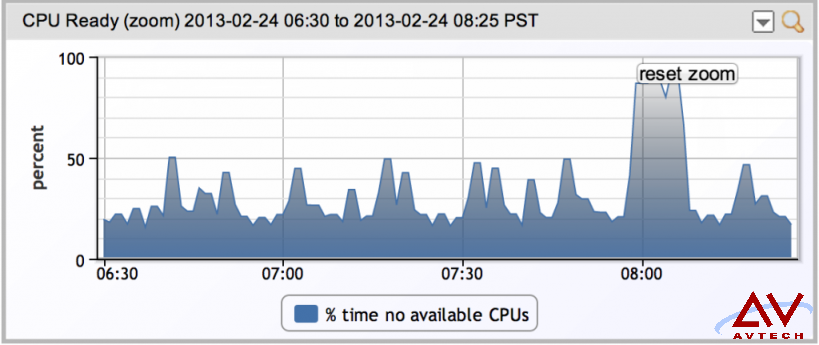
如下以 VMware 性能监控器显示只有瞬间攀升。
本文来自于艾威培训
转载请注明:https://www.avtechcn.cn/share/1307.html
